
Showing posts with label JEE. Show all posts
Showing posts with label JEE. Show all posts
Saturday, March 13, 2010
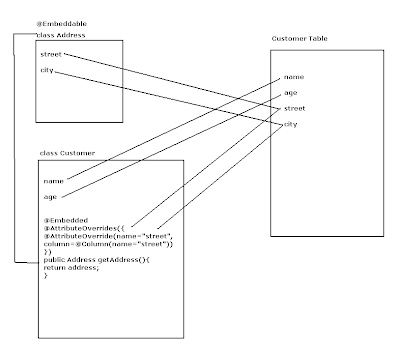
Two Entities to One Table mapping
The picture below shows how two entities can be mapped to one single table -
Two Tables to One Entity mapping
The picture below shows how two table can be mapped to one single entity -


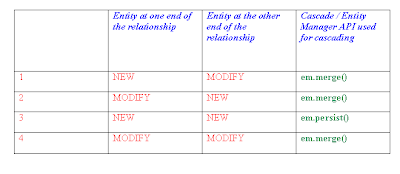
Entity Relationship Cascade
The table below shows the Entity Manager API used for cascading when you want to save entity relationship

Friday, March 12, 2010
Entity Manager Merge() Vs Persist()
Like every one knows Persist is used to create a new entry and merge is normally used to update an already existing entry but the confusion begins when we realize that merge can also be used to create a new entry as well.
So the question is why do we have persist when merge can do both update and create entries?
Here it goes -
1) Performance and Memory
Persist will just dump the entity into the database but merge will have to first figure out if this entry exists in the database for it to make out if it is a create or a update scenario. Secondly merge will copy the passed object and will save the copied object into the database, so if the entity relationship is complex this copy procedure is more time consuming and a lil memory intensive.
2) RBAC
Some roles can only update few entries and may not be allowed to create new entries or viceversa, so to have a seggregation we have seperate apis for persist and merge.
So the question is why do we have persist when merge can do both update and create entries?
Here it goes -
1) Performance and Memory
Persist will just dump the entity into the database but merge will have to first figure out if this entry exists in the database for it to make out if it is a create or a update scenario. Secondly merge will copy the passed object and will save the copied object into the database, so if the entity relationship is complex this copy procedure is more time consuming and a lil memory intensive.
2) RBAC
Some roles can only update few entries and may not be allowed to create new entries or viceversa, so to have a seggregation we have seperate apis for persist and merge.
Sunday, February 28, 2010
Flush, Persist and Merge
Flush
There are two flush modes -
1) Auto
2) Commit
Auto flush is the default which flushes [persists] the entities in the persistence context at the transaction commit time and also on every query executed with in a transaction. Exception to this is find() because if we want to find an entity which is modified then the find will return back the entity that is present in the persistence context. But if we execute a query then query doesnt return the whole entity but returns some fields as a list and this is the reason that thepersistence context is flushed during query execution.
Commit mode will flush the persistence context when the transaction commits.
We can force flush by calling the flush method on the entity manager to flush the persistence context.
Persist and Merge
Merge can persist but persist cannot merge.
When an entity is persisted and before even the transaction is not commited, we can get the primary key if the primary key is autogenerated using table strategy.
There are two flush modes -
1) Auto
2) Commit
Auto flush is the default which flushes [persists] the entities in the persistence context at the transaction commit time and also on every query executed with in a transaction. Exception to this is find() because if we want to find an entity which is modified then the find will return back the entity that is present in the persistence context. But if we execute a query then query doesnt return the whole entity but returns some fields as a list and this is the reason that thepersistence context is flushed during query execution.
Commit mode will flush the persistence context when the transaction commits.
We can force flush by calling the flush method on the entity manager to flush the persistence context.
Persist and Merge
Merge can persist but persist cannot merge.
When an entity is persisted and before even the transaction is not commited, we can get the primary key if the primary key is autogenerated using table strategy.
Persistence Context and Entity Manager
Persistence Context is nothing but a bag that holds entities. Entity Manager contains persistence context and manages [creates, updates, deletes] the entities that are part of that persistence context. This is shown in the following figure

The life cycle of persistence context depends on whether it is transaction-scoped or extended persistence context.
Transaction-Scoped Persistence Context -
Transaction begins when the bean method is invoked and it ends when the method returns or completes. Similarly transaction-scoped persistence context follows the transaction and is created when the transaction begins and ends after the transaction commits or rolls back.

Extended Persistence Context -
This type of Persistence Context is independent of transaction i.e., the creation or destruction of persistence context is not dependent on transaction begin or transaction end as in the case of transaction-scoped persistence context. Persistence Context will be created when the statefull session bean is created and it is destroyed when the stateful session bean is destroyed.

Note:
There can be many instances of Entity Manager referring to the same single instance of persistence context if all these entity managers are part of the same transaction i.e., entity manager instances part of different ejb's invoked by an ejb which starts and ends the transaction. Please refer the picture below -


The life cycle of persistence context depends on whether it is transaction-scoped or extended persistence context.
Transaction-Scoped Persistence Context -
Transaction begins when the bean method is invoked and it ends when the method returns or completes. Similarly transaction-scoped persistence context follows the transaction and is created when the transaction begins and ends after the transaction commits or rolls back.

Extended Persistence Context -
This type of Persistence Context is independent of transaction i.e., the creation or destruction of persistence context is not dependent on transaction begin or transaction end as in the case of transaction-scoped persistence context. Persistence Context will be created when the statefull session bean is created and it is destroyed when the stateful session bean is destroyed.

Note:
There can be many instances of Entity Manager referring to the same single instance of persistence context if all these entity managers are part of the same transaction i.e., entity manager instances part of different ejb's invoked by an ejb which starts and ends the transaction. Please refer the picture below -

Tuesday, November 24, 2009
Optimistic Concurrency Control by enabling versioning in Hibernate
Note:
The following article is an excerpt from the great book - "Java Persistence with Hibernate"
Choosing an isolation level
Developers (ourselves included) are often unsure what transaction isolation level
to use in a production application. Too great a degree of isolation harms scalability
of a highly concurrent application. Insufficient isolation may cause subtle,
unreproduceable bugs in an application that you’ll never discover until the system
is working under heavy load.
Note that we refer to optimistic locking (with versioning) in the following explanation,
a concept explained later in this chapter. You may want to skip this section
and come back when it’s time to make the decision for an isolation level in your
application. Picking the correct isolation level is, after all, highly dependent on
your particular scenario. Read the following discussion as recommendations, not
carved in stone.
Hibernate tries hard to be as transparent as possible regarding transactional
semantics of the database. Nevertheless, caching and optimistic locking affect
these semantics. What is a sensible database isolation level to choose in a Hibernate
application?
First, eliminate the read uncommitted isolation level. It’s extremely dangerous to
use one transaction’s uncommitted changes in a different transaction. The rollback
or failure of one transaction will affect other concurrent transactions. Rollback
of the first transaction could bring other transactions down with it, or
perhaps even cause them to leave the database in an incorrect state. It’s even possible
that changes made by a transaction that ends up being rolled back could be
committed anyway, because they could be read and then propagated by another
transaction that is successful!
Secondly, most applications don’t need serializable isolation (phantom reads
aren’t usually problematic), and this isolation level tends to scale poorly. Few
existing applications use serializable isolation in production, but rather rely on
pessimistic locks (see next sections) that effectively force a serialized execution of
operations in certain situations.
This leaves you a choice between read committed and repeatable read. Let’s first
consider repeatable read. This isolation level eliminates the possibility that one
transaction can overwrite changes made by another concurrent transaction (the
second lost updates problem) if all data access is performed in a single atomic
database transaction. A read lock held by a transaction prevents any write lock a
concurrent transaction may wish to obtain. This is an important issue, but
enabling repeatable read isn’t the only way to resolve it.
Let’s assume you’re using versioned data, something that Hibernate can do for
you automatically. The combination of the (mandatory) persistence context
cache and versioning already gives you most of the nice features of repeatable
read isolation. In particular, versioning prevents the second lost updates problem,
and the persistence context cache also ensures that the state of the persistent
instances loaded by one transaction is isolated from changes made by other transactions.
So, read-committed isolation for all database transactions is acceptable if
you use versioned data.
Repeatable read provides more reproducibility for query result sets (only for
the duration of the database transaction); but because phantom reads are still
possible, that doesn’t appear to have much value. You can obtain a repeatable-
read guarantee explicitly in Hibernate for a particular transaction and piece
of data (with a pessimistic lock).
Setting the transaction isolation level allows you to choose a good default locking
strategy for all your database transactions. How do you set the isolation level?
Setting an isolation level
Every JDBC connection to a database is in the default isolation level of the DBMS—
usually read committed or repeatable read. You can change this default in the
DBMS configuration. You may also set the transaction isolation for JDBC connections
on the application side, with a Hibernate configuration option:
hibernate.connection.isolation = 4
Hibernate sets this isolation level on every JDBC connection obtained from a
connection pool before starting a transaction. The sensible values for this option
are as follows (you may also find them as constants in java.sql.Connection):
■ 1—Read uncommitted isolation
■ 2—Read committed isolation
■ 4—Repeatable read isolation
■ 8—Serializable isolation
Note that Hibernate never changes the isolation level of connections obtained
from an application server-provided database connection in a managed environment!
You can change the default isolation using the configuration of your application
server. (The same is true if you use a stand-alone JTA implementation.)
As you can see, setting the isolation level is a global option that affects all connections
and transactions. From time to time, it’s useful to specify a more restrictive
lock for a particular transaction. Hibernate and Java Persistence rely on
optimistic concurrency control, and both allow you to obtain additional locking
guarantees with version checking and pessimistic locking.
An optimistic approach always assumes that everything will be OK and that conflicting
data modifications are rare. Optimistic concurrency control raises an
error only at the end of a unit of work, when data is written. Multiuser applications
usually default to optimistic concurrency control and database connections
with a read-committed isolation level. Additional isolation guarantees are
obtained only when appropriate; for example, when a repeatable read is required.
This approach guarantees the best performance and scalability.
Understanding the optimistic strategy
To understand optimistic concurrency control, imagine that two transactions read
a particular object from the database, and both modify it. Thanks to the read-committed
isolation level of the database connection, neither transaction will run into any dirty reads. However, reads are still nonrepeatable, and updates may also be
lost. This is a problem you’ll face when you think about conversations, which are
atomic transactions from the point of view of your users. Look at figure 10.6.
Let’s assume that two users select the same piece of data at the same time. The
user in conversation A submits changes first, and the conversation ends with a successful
commit of the second transaction. Some time later (maybe only a second),
the user in conversation B submits changes. This second transaction also commits
successfully. The changes made in conversation A have been lost, and (potentially
worse) modifications of data committed in conversation B may have been based
on stale information.
You have three choices for how to deal with lost updates in these second transactions
in the conversations:
■ Last commit wins—Both transactions commit successfully, and the second
commit overwrites the changes of the first. No error message is shown.
■ First commit wins—The transaction of conversation A is committed, and the
user committing the transaction in conversation B gets an error message.
The user must restart the conversation by retrieving fresh data and go
through all steps of the conversation again with nonstale data.
■ Merge conflicting updates—The first modification is committed, and the transaction
in conversation B aborts with an error message when it’s committed.
The user of the failed conversation B may however apply changes selectively,
instead of going through all the work in the conversation again.
If you don’t enable optimistic concurrency control, and by default it isn’t enabled,
your application runs with a last commit wins strategy. In practice, this issue of lost
updates is frustrating for application users, because they may see all their work
lost without an error message.

Figure 10.6
Conversation B overwrites
changes made by conversation A.
Obviously, first commit wins is much more attractive. If the application user of
conversation B commits, he gets an error message that reads, Somebody already committed
modifications to the data you’re about to commit. You’ve been working with stale
data. Please restart the conversation with fresh data. It’s your responsibility to design
and write the application to produce this error message and to direct the user to
the beginning of the conversation. Hibernate and Java Persistence help you with
automatic optimistic locking, so that you get an exception whenever a transaction
tries to commit an object that has a conflicting updated state in the database.
Merge conflicting changes, is a variation of first commit wins. Instead of displaying
an error message that forces the user to go back all the way, you offer a dialog that
allows the user to merge conflicting changes manually. This is the best strategy
because no work is lost and application users are less frustrated by optimistic concurrency
failures. However, providing a dialog to merge changes is much more
time-consuming for you as a developer than showing an error message and forcing
the user to repeat all the work. We’ll leave it up to you whether you want to use
this strategy.
Optimistic concurrency control can be implemented many ways. Hibernate
works with automatic versioning.
Enabling versioning in Hibernate
Hibernate provides automatic versioning. Each entity instance has a version,
which can be a number or a timestamp. Hibernate increments an object’s version
when it’s modified, compares versions automatically, and throws an exception if a
conflict is detected. Consequently, you add this version property to all your persistent
entity classes to enable optimistic locking:
public class Item {
...
private int version;
...
}
You can also add a getter method; however, version numbers must not be modified
by the application. The <version> property mapping in XML must be placed
immediately after the identifier property mapping:
<class name="Item" table="ITEM">
<id .../>
<version name="version" access="field" column="OBJ_VERSION"/>
...
</class>
The version number is just a counter value—it doesn’t have any useful semantic
value. The additional column on the entity table is used by your Hibernate application.
Keep in mind that all other applications that access the same database can
(and probably should) also implement optimistic versioning and utilize the same
version column. Sometimes a timestamp is preferred (or exists):
public class Item {
...
private Date lastUpdated;
...
}
<class name="Item" table="ITEM">
<id .../>
<timestamp name="lastUpdated"
access="field"
column="LAST_UPDATED"/>
...
</class>
In theory, a timestamp is slightly less safe, because two concurrent transactions
may both load and update the same item in the same millisecond; in practice,
this won’t occur because a JVM usually doesn’t have millisecond accuracy (you
should check your JVM and operating system documentation for the guaranteed
precision).
Furthermore, retrieving the current time from the JVM isn’t necessarily safe in
a clustered environment, where nodes may not be time synchronized. You can
switch to retrieval of the current time from the database machine with the
source="db" attribute on the mapping. Not all Hibernate SQL dialects
support this (check the source of your configured dialect), and there is
always the overhead of hitting the database for every increment.
We recommend that new projects rely on versioning with version numbers, not
timestamps.
Optimistic locking with versioning is enabled as soon as you add a
or a <timestamp> property to a persistent class mapping. There is no other switch.
How does Hibernate use the version to detect a conflict?
Automatic management of versions
Every DML operation that involves the now versioned Item objects includes a version
check. For example, assume that in a unit of work you load an Item from the
database with version 1. You then modify one of its value-typed properties, such as
the price of the Item. When the persistence context is flushed, Hibernate detects
that modification and increments the version of the Item to 2. It then executes
the SQL UPDATE to make this modification permanent in the database:
update ITEM set INITIAL_PRICE='12.99', OBJ_VERSION=2
where ITEM_ID=123 and OBJ_VERSION=1
If another concurrent unit of work updated and committed the same row, the
OBJ_VERSION column no longer contains the value 1, and the row isn’t updated.
Hibernate checks the row count for this statement as returned by the JDBC
driver—which in this case is the number of rows updated, zero—and throws a
StaleObjectStateException. The state that was present when you loaded the
Item is no longer present in the database at flush-time; hence, you’re working
with stale data and have to notify the application user. You can catch this exception
and display an error message or a dialog that helps the user restart a conversation
with the application.
What modifications trigger the increment of an entity’s version? Hibernate
increments the version number (or the timestamp) whenever an entity instance is
dirty. This includes all dirty value-typed properties of the entity, no matter if
they’re single-valued, components, or collections. Think about the relationship
between User and BillingDetails, a one-to-many entity association: If a Credit-
Card is modified, the version of the related User isn’t incremented. If you add or
remove a CreditCard (or BankAccount) from the collection of billing details, the
version of the User is incremented.
If you want to disable automatic increment for a particular value-typed property
or collection, map it with the optimistic-lock="false" attribute. The
inverse attribute makes no difference here. Even the version of an owner of an
inverse collection is updated if an element is added or removed from the
inverse collection.
As you can see, Hibernate makes it incredibly easy to manage versions for optimistic
concurrency control. If you’re working with a legacy database schema or
existing Java classes, it may be impossible to introduce a version or timestamp
property and column. Hibernate has an alternative strategy for you.
The following article is an excerpt from the great book - "Java Persistence with Hibernate"
Choosing an isolation level
Developers (ourselves included) are often unsure what transaction isolation level
to use in a production application. Too great a degree of isolation harms scalability
of a highly concurrent application. Insufficient isolation may cause subtle,
unreproduceable bugs in an application that you’ll never discover until the system
is working under heavy load.
Note that we refer to optimistic locking (with versioning) in the following explanation,
a concept explained later in this chapter. You may want to skip this section
and come back when it’s time to make the decision for an isolation level in your
application. Picking the correct isolation level is, after all, highly dependent on
your particular scenario. Read the following discussion as recommendations, not
carved in stone.
Hibernate tries hard to be as transparent as possible regarding transactional
semantics of the database. Nevertheless, caching and optimistic locking affect
these semantics. What is a sensible database isolation level to choose in a Hibernate
application?
First, eliminate the read uncommitted isolation level. It’s extremely dangerous to
use one transaction’s uncommitted changes in a different transaction. The rollback
or failure of one transaction will affect other concurrent transactions. Rollback
of the first transaction could bring other transactions down with it, or
perhaps even cause them to leave the database in an incorrect state. It’s even possible
that changes made by a transaction that ends up being rolled back could be
committed anyway, because they could be read and then propagated by another
transaction that is successful!
Secondly, most applications don’t need serializable isolation (phantom reads
aren’t usually problematic), and this isolation level tends to scale poorly. Few
existing applications use serializable isolation in production, but rather rely on
pessimistic locks (see next sections) that effectively force a serialized execution of
operations in certain situations.
This leaves you a choice between read committed and repeatable read. Let’s first
consider repeatable read. This isolation level eliminates the possibility that one
transaction can overwrite changes made by another concurrent transaction (the
second lost updates problem) if all data access is performed in a single atomic
database transaction. A read lock held by a transaction prevents any write lock a
concurrent transaction may wish to obtain. This is an important issue, but
enabling repeatable read isn’t the only way to resolve it.
Let’s assume you’re using versioned data, something that Hibernate can do for
you automatically. The combination of the (mandatory) persistence context
cache and versioning already gives you most of the nice features of repeatable
read isolation. In particular, versioning prevents the second lost updates problem,
and the persistence context cache also ensures that the state of the persistent
instances loaded by one transaction is isolated from changes made by other transactions.
So, read-committed isolation for all database transactions is acceptable if
you use versioned data.
Repeatable read provides more reproducibility for query result sets (only for
the duration of the database transaction); but because phantom reads are still
possible, that doesn’t appear to have much value. You can obtain a repeatable-
read guarantee explicitly in Hibernate for a particular transaction and piece
of data (with a pessimistic lock).
Setting the transaction isolation level allows you to choose a good default locking
strategy for all your database transactions. How do you set the isolation level?
Setting an isolation level
Every JDBC connection to a database is in the default isolation level of the DBMS—
usually read committed or repeatable read. You can change this default in the
DBMS configuration. You may also set the transaction isolation for JDBC connections
on the application side, with a Hibernate configuration option:
hibernate.connection.isolation = 4
Hibernate sets this isolation level on every JDBC connection obtained from a
connection pool before starting a transaction. The sensible values for this option
are as follows (you may also find them as constants in java.sql.Connection):
■ 1—Read uncommitted isolation
■ 2—Read committed isolation
■ 4—Repeatable read isolation
■ 8—Serializable isolation
Note that Hibernate never changes the isolation level of connections obtained
from an application server-provided database connection in a managed environment!
You can change the default isolation using the configuration of your application
server. (The same is true if you use a stand-alone JTA implementation.)
As you can see, setting the isolation level is a global option that affects all connections
and transactions. From time to time, it’s useful to specify a more restrictive
lock for a particular transaction. Hibernate and Java Persistence rely on
optimistic concurrency control, and both allow you to obtain additional locking
guarantees with version checking and pessimistic locking.
An optimistic approach always assumes that everything will be OK and that conflicting
data modifications are rare. Optimistic concurrency control raises an
error only at the end of a unit of work, when data is written. Multiuser applications
usually default to optimistic concurrency control and database connections
with a read-committed isolation level. Additional isolation guarantees are
obtained only when appropriate; for example, when a repeatable read is required.
This approach guarantees the best performance and scalability.
Understanding the optimistic strategy
To understand optimistic concurrency control, imagine that two transactions read
a particular object from the database, and both modify it. Thanks to the read-committed
isolation level of the database connection, neither transaction will run into any dirty reads. However, reads are still nonrepeatable, and updates may also be
lost. This is a problem you’ll face when you think about conversations, which are
atomic transactions from the point of view of your users. Look at figure 10.6.
Let’s assume that two users select the same piece of data at the same time. The
user in conversation A submits changes first, and the conversation ends with a successful
commit of the second transaction. Some time later (maybe only a second),
the user in conversation B submits changes. This second transaction also commits
successfully. The changes made in conversation A have been lost, and (potentially
worse) modifications of data committed in conversation B may have been based
on stale information.
You have three choices for how to deal with lost updates in these second transactions
in the conversations:
■ Last commit wins—Both transactions commit successfully, and the second
commit overwrites the changes of the first. No error message is shown.
■ First commit wins—The transaction of conversation A is committed, and the
user committing the transaction in conversation B gets an error message.
The user must restart the conversation by retrieving fresh data and go
through all steps of the conversation again with nonstale data.
■ Merge conflicting updates—The first modification is committed, and the transaction
in conversation B aborts with an error message when it’s committed.
The user of the failed conversation B may however apply changes selectively,
instead of going through all the work in the conversation again.
If you don’t enable optimistic concurrency control, and by default it isn’t enabled,
your application runs with a last commit wins strategy. In practice, this issue of lost
updates is frustrating for application users, because they may see all their work
lost without an error message.
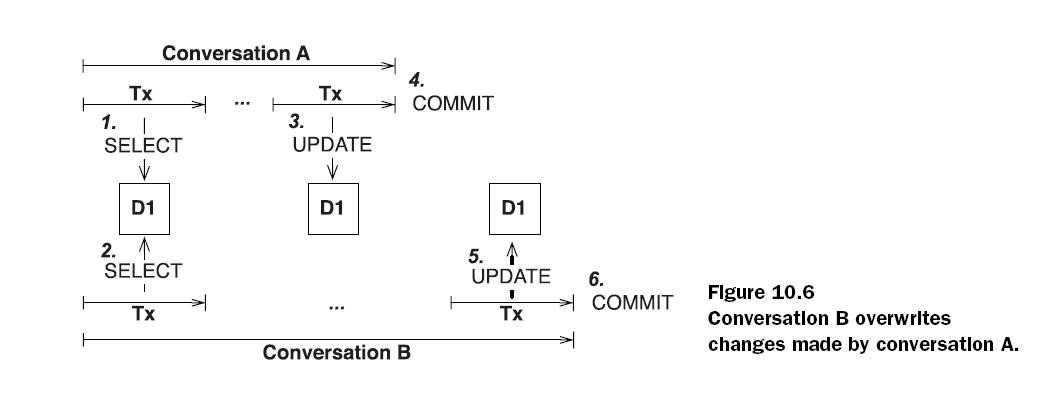
Figure 10.6
Conversation B overwrites
changes made by conversation A.
Obviously, first commit wins is much more attractive. If the application user of
conversation B commits, he gets an error message that reads, Somebody already committed
modifications to the data you’re about to commit. You’ve been working with stale
data. Please restart the conversation with fresh data. It’s your responsibility to design
and write the application to produce this error message and to direct the user to
the beginning of the conversation. Hibernate and Java Persistence help you with
automatic optimistic locking, so that you get an exception whenever a transaction
tries to commit an object that has a conflicting updated state in the database.
Merge conflicting changes, is a variation of first commit wins. Instead of displaying
an error message that forces the user to go back all the way, you offer a dialog that
allows the user to merge conflicting changes manually. This is the best strategy
because no work is lost and application users are less frustrated by optimistic concurrency
failures. However, providing a dialog to merge changes is much more
time-consuming for you as a developer than showing an error message and forcing
the user to repeat all the work. We’ll leave it up to you whether you want to use
this strategy.
Optimistic concurrency control can be implemented many ways. Hibernate
works with automatic versioning.
Enabling versioning in Hibernate
Hibernate provides automatic versioning. Each entity instance has a version,
which can be a number or a timestamp. Hibernate increments an object’s version
when it’s modified, compares versions automatically, and throws an exception if a
conflict is detected. Consequently, you add this version property to all your persistent
entity classes to enable optimistic locking:
public class Item {
...
private int version;
...
}
You can also add a getter method; however, version numbers must not be modified
by the application. The <version> property mapping in XML must be placed
immediately after the identifier property mapping:
<class name="Item" table="ITEM">
<id .../>
<version name="version" access="field" column="OBJ_VERSION"/>
...
</class>
The version number is just a counter value—it doesn’t have any useful semantic
value. The additional column on the entity table is used by your Hibernate application.
Keep in mind that all other applications that access the same database can
(and probably should) also implement optimistic versioning and utilize the same
version column. Sometimes a timestamp is preferred (or exists):
public class Item {
...
private Date lastUpdated;
...
}
<class name="Item" table="ITEM">
<id .../>
<timestamp name="lastUpdated"
access="field"
column="LAST_UPDATED"/>
...
</class>
In theory, a timestamp is slightly less safe, because two concurrent transactions
may both load and update the same item in the same millisecond; in practice,
this won’t occur because a JVM usually doesn’t have millisecond accuracy (you
should check your JVM and operating system documentation for the guaranteed
precision).
Furthermore, retrieving the current time from the JVM isn’t necessarily safe in
a clustered environment, where nodes may not be time synchronized. You can
switch to retrieval of the current time from the database machine with the
source="db" attribute on the
support this (check the source of your configured dialect), and there is
always the overhead of hitting the database for every increment.
We recommend that new projects rely on versioning with version numbers, not
timestamps.
Optimistic locking with versioning is enabled as soon as you add a
or a <timestamp> property to a persistent class mapping. There is no other switch.
How does Hibernate use the version to detect a conflict?
Automatic management of versions
Every DML operation that involves the now versioned Item objects includes a version
check. For example, assume that in a unit of work you load an Item from the
database with version 1. You then modify one of its value-typed properties, such as
the price of the Item. When the persistence context is flushed, Hibernate detects
that modification and increments the version of the Item to 2. It then executes
the SQL UPDATE to make this modification permanent in the database:
update ITEM set INITIAL_PRICE='12.99', OBJ_VERSION=2
where ITEM_ID=123 and OBJ_VERSION=1
If another concurrent unit of work updated and committed the same row, the
OBJ_VERSION column no longer contains the value 1, and the row isn’t updated.
Hibernate checks the row count for this statement as returned by the JDBC
driver—which in this case is the number of rows updated, zero—and throws a
StaleObjectStateException. The state that was present when you loaded the
Item is no longer present in the database at flush-time; hence, you’re working
with stale data and have to notify the application user. You can catch this exception
and display an error message or a dialog that helps the user restart a conversation
with the application.
What modifications trigger the increment of an entity’s version? Hibernate
increments the version number (or the timestamp) whenever an entity instance is
dirty. This includes all dirty value-typed properties of the entity, no matter if
they’re single-valued, components, or collections. Think about the relationship
between User and BillingDetails, a one-to-many entity association: If a Credit-
Card is modified, the version of the related User isn’t incremented. If you add or
remove a CreditCard (or BankAccount) from the collection of billing details, the
version of the User is incremented.
If you want to disable automatic increment for a particular value-typed property
or collection, map it with the optimistic-lock="false" attribute. The
inverse attribute makes no difference here. Even the version of an owner of an
inverse collection is updated if an element is added or removed from the
inverse collection.
As you can see, Hibernate makes it incredibly easy to manage versions for optimistic
concurrency control. If you’re working with a legacy database schema or
existing Java classes, it may be impossible to introduce a version or timestamp
property and column. Hibernate has an alternative strategy for you.
Transaction Isolation Levels
Dirty Read
A dirty read occurs if a one transaction reads changes made by another transaction
that has not yet been committed. This is dangerous, because the changes made by
the other transaction may later be rolled back, and invalid data may be written by
the first transaction, as shown in the figure

Non-repeatable Read
An unrepeatable read occurs if a transaction reads a row twice and reads different
state each time. For example, another transaction may have written to the row
and committed between the two reads as shown in the figure

Phantom Read
A phantom read is said to occur when a transaction executes a query twice, and
the second result set includes rows that weren’t visible in the first result set or rows
that have been deleted. (It need not necessarily be exactly the same query.) This
situation is caused by another transaction inserting or deleting rows between the
execution of the two queries as shown in the figure

Lost update
A lost update occurs if two transactions both update a row and then the second
transaction aborts, causing both changes to be lost. This occurs in systems that
don’t implement locking.
Transaction Isolation Levels
Read Uncommitted
A system that permits dirty reads but not lost updates is said to operate in
read uncommitted isolation. One transaction may not write to a row if another
uncommitted transaction has already written to it. Any transaction may read
any row, however.
Read Committed
A system that permits unrepeatable reads but not dirty reads is said to implement
read committed transaction isolation. This may be achieved by using
shared read locks and exclusive write locks. Reading transactions don’t
block other transactions from accessing a row. However, an uncommitted
writing transaction blocks all other transactions from accessing the row.
Repeatable Read
A system operating in repeatable read isolation mode permits neither unrepeatable
reads nor dirty reads. Phantom reads may occur. Reading transactions
block writing transactions (but not other reading transactions), and
writing transactions block all other transactions.
Serializable
Serializable provides the strictest transaction isolation. This isolation level
emulates serial transaction execution, as if transactions were executed one
after another, serially, rather than concurrently. Serializability may not be
implemented using only row-level locks. There must instead be some other
mechanism that prevents a newly inserted row from becoming visible to a
transaction that has already executed a query that would return the row.
A dirty read occurs if a one transaction reads changes made by another transaction
that has not yet been committed. This is dangerous, because the changes made by
the other transaction may later be rolled back, and invalid data may be written by
the first transaction, as shown in the figure

Non-repeatable Read
An unrepeatable read occurs if a transaction reads a row twice and reads different
state each time. For example, another transaction may have written to the row
and committed between the two reads as shown in the figure

Phantom Read
A phantom read is said to occur when a transaction executes a query twice, and
the second result set includes rows that weren’t visible in the first result set or rows
that have been deleted. (It need not necessarily be exactly the same query.) This
situation is caused by another transaction inserting or deleting rows between the
execution of the two queries as shown in the figure

Lost update
A lost update occurs if two transactions both update a row and then the second
transaction aborts, causing both changes to be lost. This occurs in systems that
don’t implement locking.
Transaction Isolation Levels
Read Uncommitted
A system that permits dirty reads but not lost updates is said to operate in
read uncommitted isolation. One transaction may not write to a row if another
uncommitted transaction has already written to it. Any transaction may read
any row, however.
Read Committed
A system that permits unrepeatable reads but not dirty reads is said to implement
read committed transaction isolation. This may be achieved by using
shared read locks and exclusive write locks. Reading transactions don’t
block other transactions from accessing a row. However, an uncommitted
writing transaction blocks all other transactions from accessing the row.
Repeatable Read
A system operating in repeatable read isolation mode permits neither unrepeatable
reads nor dirty reads. Phantom reads may occur. Reading transactions
block writing transactions (but not other reading transactions), and
writing transactions block all other transactions.
Serializable
Serializable provides the strictest transaction isolation. This isolation level
emulates serial transaction execution, as if transactions were executed one
after another, serially, rather than concurrently. Serializability may not be
implemented using only row-level locks. There must instead be some other
mechanism that prevents a newly inserted row from becoming visible to a
transaction that has already executed a query that would return the row.
Sunday, November 22, 2009
Managing User Preferences - Personalize the User Space
Managing User Preferences
User does many things once he logins into the application to personalize his space.
Some of the many things will be setting the window sizes, positioning the windows, hiding or showing widgets etc etc.
Here I will briefly go through how to manage user preferences in ext js.
Initialize the state provider
Ext.state.Manager.setProvider(new HttpProvider());
In this case we are initializing the manager with the Http state provider persisting the state to the database.
Initialize the scheduler
Scheduler in this case will schedule the task for persisting the state to the database.
delayedTask = new Ext.util.DelayedTask(this.persistState, this);
Here DelayedTask is used as the scheduler.
Initialize the state manager
Initialize the state manager by loading any state persisted before by reading it from the database via HttpProvider.
Start the scheduler
delayedTask.delay(1000);
Here we are asking the scheduler to poll the state manager once in 1000 milli seconds to know if there are any changes in the state to be persisted.
The callback api, in this case, the persistState api will be called if there are any changes to the state.
persistState api may look like this,
function persistState() {
if(!stateDirty) {
delayedTask.delay(1000); // If state not dirty delay the scheduler for 1000 milliseconds more
}
delayedTask.cancel(); // stop the scheduler and submit the state to the server asking it to persist to the database.
submitState();
}
Override the set method of the provider
Set method of the provider is used to set the state [user preference like window size, x & y position etc] to the state manager.
Override the set method of the Provider to set the stateDirty flag to true and start the scheduler which was cancelled when the state was submitted to the server.
stateDirty = true;
delayedTask.delay(1000);
superclass.set();
User does many things once he logins into the application to personalize his space.
Some of the many things will be setting the window sizes, positioning the windows, hiding or showing widgets etc etc.
Here I will briefly go through how to manage user preferences in ext js.
Initialize the state provider
Ext.state.Manager.setProvider(new HttpProvider());
In this case we are initializing the manager with the Http state provider persisting the state to the database.
Initialize the scheduler
Scheduler in this case will schedule the task for persisting the state to the database.
delayedTask = new Ext.util.DelayedTask(this.persistState, this);
Here DelayedTask is used as the scheduler.
Initialize the state manager
Initialize the state manager by loading any state persisted before by reading it from the database via HttpProvider.
Start the scheduler
delayedTask.delay(1000);
Here we are asking the scheduler to poll the state manager once in 1000 milli seconds to know if there are any changes in the state to be persisted.
The callback api, in this case, the persistState api will be called if there are any changes to the state.
persistState api may look like this,
function persistState() {
if(!stateDirty) {
delayedTask.delay(1000); // If state not dirty delay the scheduler for 1000 milliseconds more
}
delayedTask.cancel(); // stop the scheduler and submit the state to the server asking it to persist to the database.
submitState();
}
Override the set method of the provider
Set method of the provider is used to set the state [user preference like window size, x & y position etc] to the state manager.
Override the set method of the Provider to set the stateDirty flag to true and start the scheduler which was cancelled when the state was submitted to the server.
stateDirty = true;
delayedTask.delay(1000);
superclass.set();
Sunday, November 15, 2009
Shopping Cart: Project set up & Login Screen
1) Create new project
Project is the collection of modules.
2) Create Modules
Module is the collection of facets.
3) There are lots of facets but 4 facets are quiet important to make a note of
Web, EJB, JPA and JEE facets.

4) Write a web.xml for your application in the web facet.

5) Configure an authenticator valve in context.xml

6) Write a redirect servlet
7) Mention about the module in application.xml

8) Configure JBoss from the ide.


9) Compile the application, deploy and run jboss.
How does it all work
When the user points the browser to localhost:8080/shoppingcart for the first time, the jboss server figures out from the web.xml configuration that this resource cannot be accessed publicly by everyone and that it needs to be secured and only allowed roles can access it. To authenticate the jboss server will use the FormAuthenticator which is configured as the valve in context.xml. The FormAuthenticator will interpret the request and changes the url to the one mentioned in web.xml, in this case it is /unsecured/login and redirects to RedirectServlet. The RedirectServlet will dispatch the request to Login.jsp and hence the Login.jsp is sent back to the browser.
Project is the collection of modules.
2) Create Modules
Module is the collection of facets.

3) There are lots of facets but 4 facets are quiet important to make a note of
Web, EJB, JPA and JEE facets.

4) Write a web.xml for your application in the web facet.

5) Configure an authenticator valve in context.xml

6) Write a redirect servlet
package com.shoppingcart.security.login;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.ServletException;
import javax.servlet.RequestDispatcher;
import java.io.IOException;
import java.util.Enumeration;
public class RedirectServlet extends HttpServlet
{
protected void service(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse) throws ServletException, IOException
{
final String svlpath = httpServletRequest.getServletPath();
Enumeration en = httpServletRequest.getAttributeNames();
String actualReqPathKey = "javax.servlet.forward.servlet_path";
String actualReqPath = (String)httpServletRequest.getAttribute(actualReqPathKey);
String pageName = actualReqPath;
if ("/unsecured/login".equals(svlpath)) {
if("/index.jsp".equals(actualReqPath)) {
pageName = "/Login.jsp";
}
}
else {
throw new ServletException("RedirectServlet: operation '" + svlpath + "' not supported!");
}
redirectToLogin(httpServletRequest, httpServletResponse, pageName);
}
private void redirectToLogin(HttpServletRequest request, HttpServletResponse response, String pageName) throws IOException, ServletException
{
RequestDispatcher dispatcher = this.getServletContext().getContext("/shoppingcart").getRequestDispatcher(pageName);
if (dispatcher != null) {
response.setContentType("text/html");
dispatcher.include(request, response);
}
}
}
7) Mention about the module in application.xml

8) Configure JBoss from the ide.


9) Compile the application, deploy and run jboss.
How does it all work
When the user points the browser to localhost:8080/shoppingcart for the first time, the jboss server figures out from the web.xml configuration that this resource cannot be accessed publicly by everyone and that it needs to be secured and only allowed roles can access it. To authenticate the jboss server will use the FormAuthenticator which is configured as the valve in context.xml. The FormAuthenticator will interpret the request and changes the url to the one mentioned in web.xml, in this case it is /unsecured/login and redirects to RedirectServlet. The RedirectServlet will dispatch the request to Login.jsp and hence the Login.jsp is sent back to the browser.
Tuesday, August 4, 2009
New Features in Java EE 6
Enterprise JavaBeans 3.1
One of the main goals of the EJB 3.1 specification is to make EJB as simple as possible. The idea is to provide more emphasis on simplifying EJB architecture while introducing new functionalities. Some of the important changes in EJB 3.1 are:
 |
- Removal of local business interface: EJB 3.0 removed the complex home and remote interfaces and made way for the plain old Java interface (POJI). EJB 3.1 goes one step further by dictating that business interfaces also are not mandatory. Similar to POJOs such as entities in JPA and message-driven beans, developers can write session beans without business interfaces in Java EE 6:
@Stateless
public class StockQuoteBean {
public double getStockPrice(String symbol) {
...
}
} - Introduction of Singleton beans: The concept of Singleton beans was introduced primarily to share application-wide data and support concurrent access. When a bean is marked as a Singleton, the container guarantees a single instance per JVM that is shared across the application tier. This provision works well for caching. Singleton beans are like any other EJBs; they are POJOs that developers can mark as Singleton beans through annotations.
All Singleton beans are transactional and thread safe by default, making way for flexible concurrency options. Java EE 6 also introduces concurrency annotations to perform locked read/write operations on getter and setter methods.@Singleton
@Startup
public class CounterBean {
private int count;
@PostConstruct
public void initialize() {
count=5;
}
} - Packaging EJB components directly in a WAR file: One of the major advancements in EJB 3.1 is the option for including EJB in a WAR file directly instead of creating a separate JAR file. EJB 3.1 provides a simplified packaging mechanism for web applications, including EJBs. Figure 2 shows how packaging was done prior to EJB 3.1.
With EJB 3.1, developers can place the EJBs directly under the classes directory in the WAR file, along with the servlets. Figure 3 shows packaging in EJB 3.1.
Figure 2. Post List Page with Tags: This is how packaging was done prior to EJB 3.1.
Figure 3. EJB 3.1 Packaging Structure: Here is packaging in EJB 3.1. - Embeddable API for executing EJB in Java SE environment: The idea behind this feature is to allow EJBs to run in Java SE environments; that is, the client and the EJB run in the same JVM. To run EJBs, Java EE 6 provides an embedded EJB container and uses JNDI for lookup. This is to facilitate better support for testing, batch processing, and using EJB from the desktop applications. The embeddable EJB container provides an environment to manage EJB. The environment supports a limited set of services. The javax.ejb.EJBContainer class represents an embeddable container.
- Asynchronous Session Bean: A session bean can support asynchronous method invocations. Bean methods annotated with @Asynchronous are invoked asynchronously. Prior to EJB 3.1, any method invocation on a session bean was always synchronous.
Asynchronous methods can return a Futureobject of the java.util.concurrent API. This will be useful for the client to get the status of the invocation, retrieve the return value of a method, check for an exception, or even cancel the invocation. 
Figure 4. EJB 3.1 Lite vs. EJB 3.1 Full: Here is a list of features supported in the full EJB API versus those supported in EJB Lite. - EJB Lite: The concept of profiles is applied to the EJB specification as well. Many enterprise applications do not require the complete set of features in EJB, so EJB Lite, a minimal subset of the EJB API, is introduced in EJB 3.1. EJB Lite includes all the features required for creating an enterprise application, but it excludes specialized APIs.
EJB Lite provides vendors the option to implement a subset of the EJB APIs within their products. Applications created with EJB Lite can be deployed on any server that supports EJB technology, irrespective of whether it is full EJB or EJB Lite. Embeddable containers support EJB Lite.
EJB Lite has the following subset of the EJB API:- Session bean components (Stateless, stateful, singleton session beans)
- Supports only synchronous invocation
- Container-managed and bean-managed transactions
- Declarative and programmatic security
- Interceptors
- Support for deployment descriptor (ejb-jar.xml)
Subscribe to:
Posts (Atom)