Advanced JBoss Class Loading
Introduction
One of the main concerns of a developer writing hot re-deployable JBoss applications is to understand how JBoss class loading works. Within the internals of the class loading mechanism lies the answer to questions like
What happens if I pack a newer version of an utility library with my application, while an older version of the same library lingers somewhere in the server's lib directory?
How can I use two different versions of the same utility library, simultaneously, within the same instance of the application server?
What version of an utility class I am currently using?
or even the most fundamental of them all
This article tries to provide the reader with the knowledge required to answer these questions. It will start by trying to answer the last one, and then it will present several often encountered use cases and explain the behavior of the JBoss class loading mechanism when faced with those situations.
The Need for Class Loaders and Class Loading Management
Class Namespace Isolation
An application server should ideally give its deployed applications the freedom to use whatever utility library and whatever version of the library they see fit, regardless of the presence of concurrent applications that want to use the same library. This is mandated by the J2EE specifications, which calls it class namespace isolation (Java EE 5 Specifications, Section EE.8.4). The fact that different applications load their classes in different class name spaces or class loading domains allow them to do just that: run whatever class version they like, oblivious to the fact that their neighbors use the same class.
Java doesn't provide the formal notion of class version. So how is it possible to implement a class loading domain? The runtime identity of a class in Java 2 is defined by the fully qualified class name and its defining class loader. This means that the same class, loaded by two different class loaders, is seen by the Virtual Machine as two completely different types.
If you like history, you probably know that this wasn't always the case. In Java 1.1 the runtime identity of a class was defined only by its fully qualified class name. That made Vijay Saraswat declare in 1997 that "[Java is not type-safe|http://matrix.research.att.com/vj/bug.html]" and Sheng Liang and Gilad Bracha fixed it by strengthening the type system to include a class's defining class loader in addition to the name of the class to fully define the type. This is good and ... not so good. It is good because now its not possible anymore that a rogue class loader would re-define your "java.lang.String" class. The VM will detect that and throw a ClassCastException. It is also good because now it is possible to have class loading domains within the same VM. Not so good however, is the fact that passing an object instance by reference between two class loading domains is not possible. Doing so results in the dreaded ClassCastException. If you would like to know more details about how this happens, please follow this link. Not being able to pass an Object by reference means you have to fall back on serialization and serialization means performance degradation.
Hot Redeployment
Returning to application servers, the need for class loaders becomes probably obvious: this is how an application server implements class namespace isolation: each application gets its own class loader at deployment, and hence, its own "version" of classes.
To extend this even more, it would be nice if we could re-deploy an application (i.e. instantiate a newer version of a class), at run-time, without necessarily bringing down the VM and re-starting it to reload the class. That would mean 24x7 uptime. Java 4 doesn't intrinsically support the concept of hot re-deployment. Once a dependent class reference was added to the runtime constant pool of a class, it is not possible to drop that reference anymore.
However, it is possible to trick the server (or the VM) into doing this. If application A interacts with application B, but doesn't have any direct references to the B classes, and B changes, let's say a newer and better version becomes available, it is possible to create a new class loader, load the new B classes and have the invocation bus (the application server) route all invocations from A to the new B classes. This way, A deals with a new version of B without even knowing it. If the application server is careful to drop all explicit references to the old B classes, they will eventually be garbage collected and the old B will eventually disappear from the system.
Sharing Classes
Isolating class loading domains is nice. Our applications will run happily and safe. But very slowly, when it comes to interacting with each other. This is because each interaction involves passing arguments by value, which means serialization, which means overhead.
We're sometimes (actually quite often) faced with the situation where in we would like to allow applications to share classes. We know precisely, for example, that in our environment, application A and B, otherwise independent, will always use the same version of the utility library and doing so, they could pass references among themselves without any problem. The added benefit in this case is that the invocations will be faster, given the fact serialization is cut out.
One word of caution though. In this situation, if we hot redeploy the utility library, we also must re-deploy the application A and B: the current A and B classes used direct references to the utility classes, so they're tainted forever, they won't ever be able to use the new utility classes.
JBoss makes possible for applications to share classes. JBoss 3.x does that by default. JBoss 4.0 does this for the "standard" configuration, but maintains class namespace isolation between applications for its "default" configuration. JBoss 4.0.1 reverts to the 3.x convention.
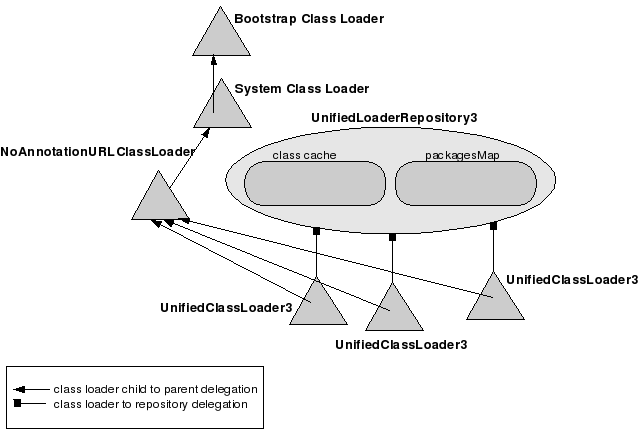
Class Repositories or How JBoss Class Loading Works
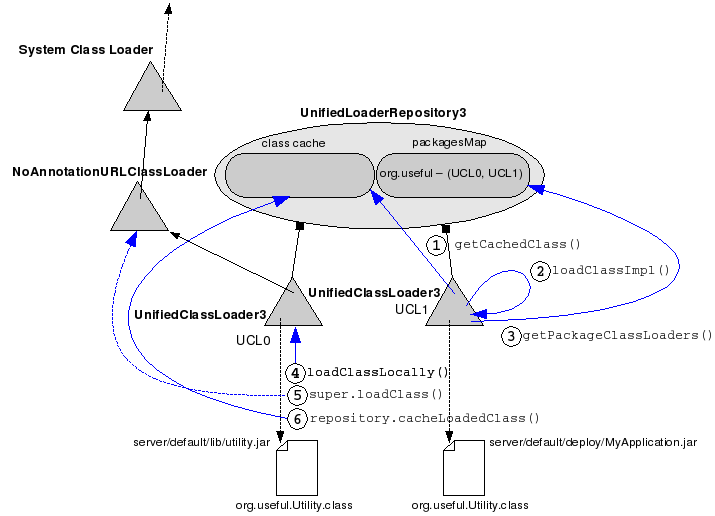
JBoss makes sharing classes possible by introducing the concept of class loader repository. The central piece of the class loading mechanism is the org.jboss.mx.loading.UnifiedClassLoader3 (UCL). UnifiedClassLoader3 extends URLClassLoader. Each UCL is associated with a shared repository of classes and resources, usually an instance of org.jboss.mx.loading.UnifiedLoaderRepository3. Every UCL is associated with a single instance of UnifiedLoaderRepository3, but a repository can have multiple UCLs. A UCL may have multiple URLs associated with it for class and resource loading. By default, there is a single UnifiedLoaderRepository3 shared across all UCL instances. UCLs form a single flat class namespace.
The class loader parent for each UCL is a NoAnnotationClassLoader instance. The NoAnnotationClassLoader extends URLClassLoader. A singleton NoAnnotationClassLoader instance is created during the server's boot process and its job is to define classes available in the $JBOSS_HOME/lib libraries (ex: commons-logging.jar, concurrent.jar, dom4j.jar, jboss-common.jar, jboss-jmx.jar, jboss-system.jar, log4j-boot.jar, xercesImpl.jar, etc.). The NoAnnotationClassLoader's parent is the system class loader (sun.misc.Launcher$AppClassLoader).

When a new UCL is created and associated with the repository, it contributes to the repository a map of packages it can potentially serve classes from. It doesn't add any class to the repository's class cache yet, because nobody has requested any class at this stage. The repository just walks through the class loader's URL to see what packages that UCL is capable of handling. So, the UCL just declares that it can potentially serve classes from the packages that are present in its classpath.
When requested to load a class, a UCL overrides the standard Java2 class loading model by first trying to load a class from its associated repository's cache. If it doesn't find it there, it delegates the task of loading the class to the first UCL associated with the repository that declared it can load that class. The order in which the UCLs have been added to the repository becomes important, because this is what defines "first" in this context. If no "available" UCL is found, the initiating UCL falls back to the standard Java2 parent delegation. This explains why you are still able to use "java.lang.String", for example.
At the end of this process, if no class definition is found in the bootstrap libraries, in the $JBOSS_HOME/lib libraries nor among the libraries associated with the repository's UCL, the UCL throws a ClassNotFoundException. However, if one of the pair UCL is able to load the class, the class will be added to the repository's class cache and from this moment on, it will be returned to any UCL requesting it.
Even if the Java bootstrap packages or $JAVA_HOME/lib packages are not added to the repository's package map, the classes belonging to those packages can be loaded through the process described above and they are added to the repository too. This explains why you'll find "java.lang.String" in the repository.
Note: Package Map is nothing but ...
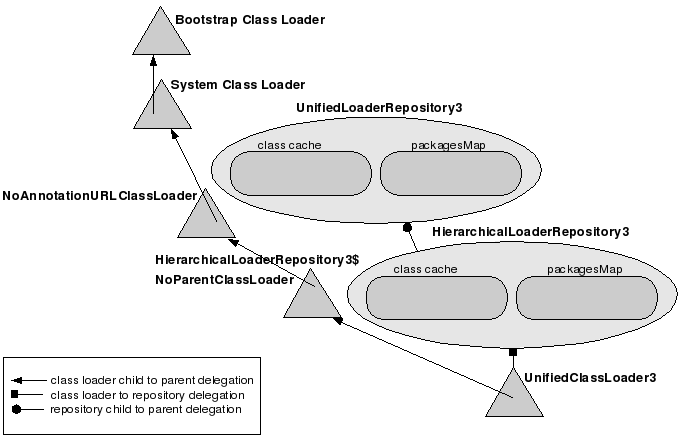
Class sharing can be turned off. J2EE-style class namespace isolation is available. You get an "isolated" application by scoping the application's deployment. At the JBoss class loading management system level, scoping translates into creating a child repository. A scoped application still can load the classes present in the classpaths of the UCLs or the root repository. Depending on whether repository's "Java2ParentDelegation" flag is turned on or off, a scoped application even has access to the class instances available in the root repository's cache. However, sibling child repositories can never share classes.

Note: Even if an HierarchicalLoaderRepository3$NoParentClassLoader instance has its parent set to be an instance of NoAnnotationURLClassLoader, as represented above, the NoParentClassLoader implementation of loadClass() always throws a ClassNotFoundException to force the UCL to only load from its URLs. We will look closer at how NoParentClassLoader works and how a scoped application loads a class available in the system's bootstrap libraries when we present the Cases 3 and 4, below.
Real World Scenarios
We will explore the complex interactions presented above based on concrete use cases.
We start by assuming that we want to deploy our own application (be it a JBoss service, a complex enterprise archive or a simple stateless session bean), and this application relies on an external library. For simplicity, we could assume that the utility library contains only a single class, org.useful.Utility. The Utility class can be packed together with the application classes inside the application archive, or it could be packed in its own archive, utility.jar. We could also assume that we always use the JBoss' default configuration.
Our hypothetical application consists of a single class, org.pkg1.A. We will consider several common situations:
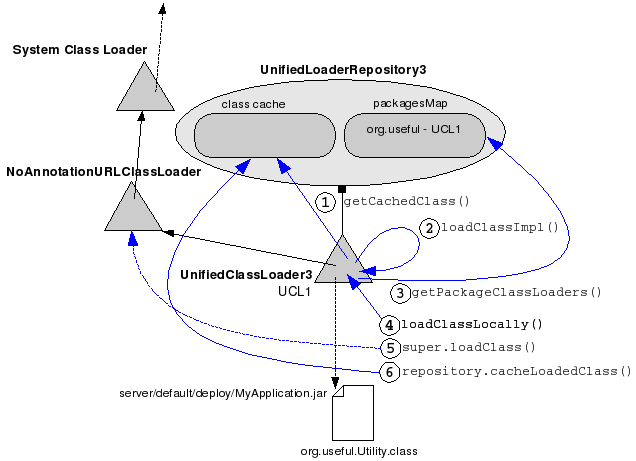
Case 1. The Utility.class is present in the application's archive, but nowhere else on the server.
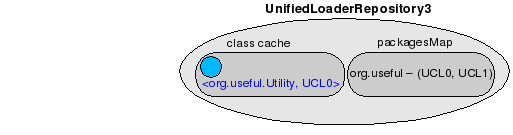
The short story: The current UCL will become the defining class loader of the class, and the class will be added to the repository's class cache. The details of the process are presented below.

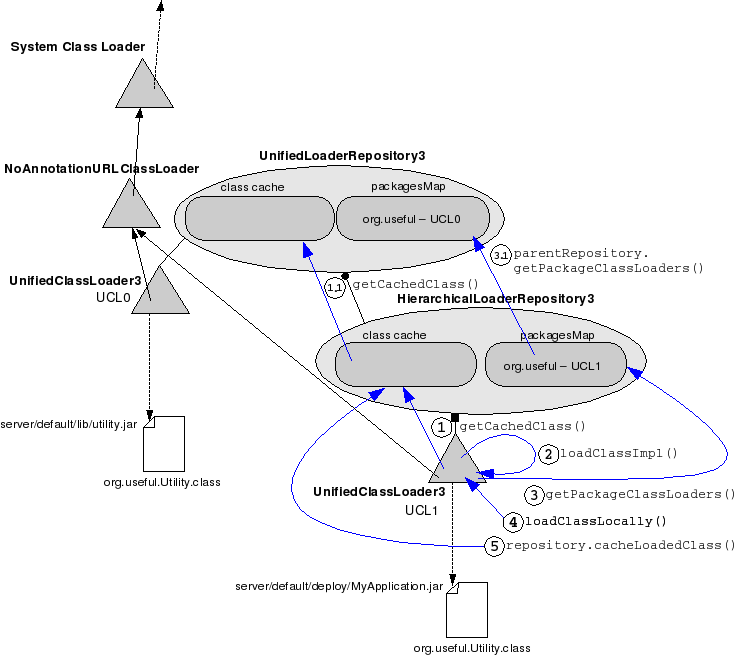
First time the application needs to use a strong-typed Utility reference, the VM asks the current UCL to load the class. The UCL tries to get the class from the repository's cache (1). If it is found, the class is returned and the process stops right here. If the class is not found, the UCL queries the repository for UCLs capable to load classes from the package the unknown class is part of (3). Being the single UCL able to define the class, the control returns to it and load manager calls loadClassLocally() on it (4). loadClassLocally() first tries to call super.loadClass() (5), which ends by involving the NoAnnotationClassLoader in the loading process. If the class is present in the bootstrap libraries or $JBOSS_HOME/lib (the URLs associated with the NoAnnotationClassLoader instance), it is loaded. Otherwise, the class is loaded from the URLs associated with the current UCL. Finally, the class is added to the repository's class cache (6).
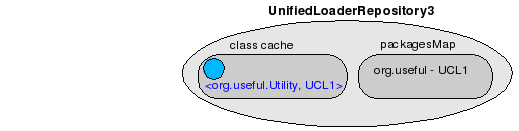
This is the configuration of the UnifiedLoaderRepository after the class loading takes place.

Case 2. The Utility.class is present both in the application's archive AND server/default/lib. The deployment is non-scoped.
The short story: The version of the class available in server/default/lib/utility.jar will be used by the new deployment. The version of the class packed with the deployment will be ignored.

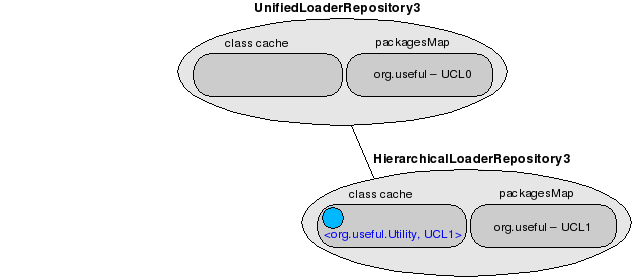
The key element here is that when getPackageClassLoaders() is invoked on the repository, the method calls returns two potential classloaders that can load org.useful.Utility: UCL0 and UCL1. The UCL0 is chosen, because it was added to the repository before UCL1 and it will be used to load org.useful.Utility.
This is the configuration of the UnifiedLoaderRepository after the class loading takes place.

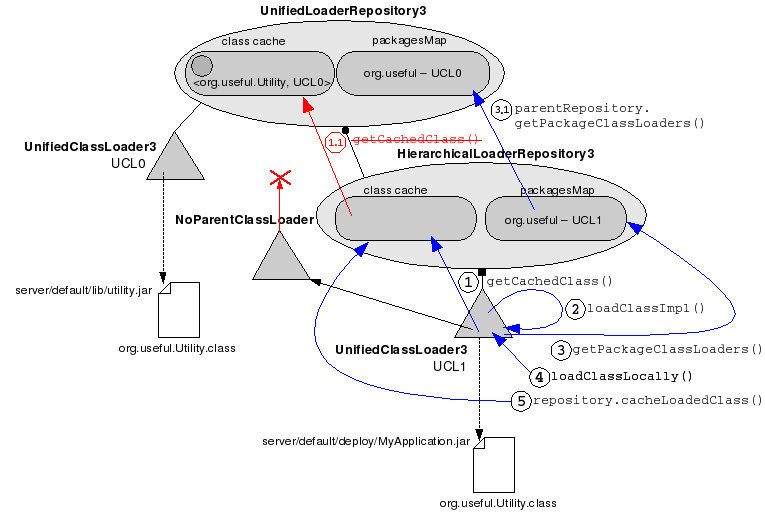
Case 3. The Utility.class is present both in the application's archive AND server/default/lib. The deployment is scoped and Java2ParentDelegation is turned off (default).
The short story: The utility class is loaded from the application's archive.

Because Java2ParentDelegation is turned off by default, the Step (1.1) is never executed, parentRepository.getCachedClass() never gets called, so the UCL doesn't have access to the repository's cached classes.
Within the scope of the call to getPackageClassLoaders() at Step 3, the child repository also calls getPackageClassLoaders() on its parent, and also includes into the returned class loader set a UCL (constructed on the spot and associated to the child repository) that has among its ancestors an instance of NoAnnotationURLClassLoader, which ultimately can reach the system class loader. Why is that? Remember that the UCL's parent, HierarchicalLoaderRepository3$NoParentClassLoader, overrides loadClass() to always throw a ClassNotFoundException, thus forcing the UCL to only load from its URLs. If the UCL relies only on its class loader parent to load bootstrap classes, it will throw ClassNotFoundException and fail when your application wants to load "java.lang.String", for example. The NoAnnotationURLClassLoader-delegating UCL instance included in the return set provides a way load bootstrap library classes.
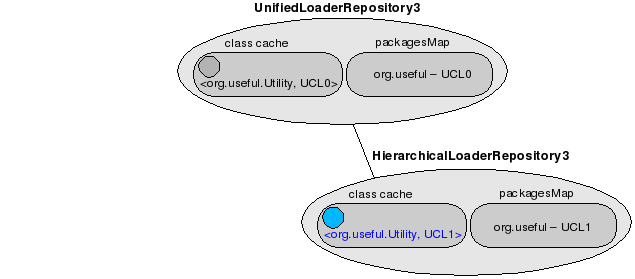
Always the HierarchialLoaderRepository's class loaders take precedence over the parent's (their "order" is lower). For the case depicted above, UCL1 is the preferred class loader.
This is the configuration of the UnifiedLoaderRepository after the class loading takes place.

Case 4. The Utility.class is present both in the application's archive AND server/default/lib. The deployment is scoped, but java2ParentDelegation is turned on.

When Java2ParentDelegation is turned on, the Step (1.1) is executed, and if a cached class is found in the parent repository, it is returned and the process stops here.
Within the scope of the call to getPackageClassLoaders() at Step (3), the child repository also calls getPackageClassLoaders() on its parent, but does not include into the returned class loader set a UCL with a parent to the system class loader. If there are no class loaders in the repository capable of handling the request ask the class loader itself in the event that its parent(s) can load the class (repository.loadClassFromClassLoader())
The HierarchialLoaderRepository's class loaders take precedence over the parent's (their "order" is lower). For the case depicted above, UCL1 is the preferred class loader.
This is the configuration of the UnifiedLoaderRepository after the class loading takes place.

Question: What happens if the parent delegation is true and a classloader already loaded the class in the parent repository's class cache?
Answer: My scoped application will use the already loaded class from the parent repository's class cache.
-
TO_DO
Explain how UCL3 are created, by whom and why. Explain the relationship between UCL created during an EAR deployment. Multiple UCLs are created (the one corresponding to the EAR and then for the embedded JARs, WARs, etc).