Note:
The following article is an excerpt from the great book - "Java Persistence with Hibernate"Choosing an isolation levelDevelopers (ourselves included) are often unsure what transaction isolation level
to use in a production application. Too great a degree of isolation harms scalability
of a highly concurrent application. Insufficient isolation may cause subtle,
unreproduceable bugs in an application that you’ll never discover until the system
is working under heavy load.
Note that we refer to optimistic locking (with versioning) in the following explanation,
a concept explained later in this chapter. You may want to skip this section
and come back when it’s time to make the decision for an isolation level in your
application. Picking the correct isolation level is, after all, highly dependent on
your particular scenario. Read the following discussion as recommendations, not
carved in stone.
Hibernate tries hard to be as transparent as possible regarding transactional
semantics of the database. Nevertheless, caching and optimistic locking affect
these semantics. What is a sensible database isolation level to choose in a Hibernate
application?
First, eliminate the read uncommitted isolation level. It’s extremely dangerous to
use one transaction’s uncommitted changes in a different transaction. The rollback
or failure of one transaction will affect other concurrent transactions. Rollback
of the first transaction could bring other transactions down with it, or
perhaps even cause them to leave the database in an incorrect state. It’s even possible
that changes made by a transaction that ends up being rolled back could be
committed anyway, because they could be read and then propagated by another
transaction that is successful!
Secondly, most applications don’t need serializable isolation (phantom reads
aren’t usually problematic), and this isolation level tends to scale poorly. Few
existing applications use serializable isolation in production, but rather rely on
pessimistic locks (see next sections) that effectively force a serialized execution of
operations in certain situations.
This leaves you a choice between read committed and repeatable read. Let’s first
consider repeatable read. This isolation level eliminates the possibility that one
transaction can overwrite changes made by another concurrent transaction (the
second lost updates problem) if all data access is performed in a single atomic
database transaction. A read lock held by a transaction prevents any write lock a
concurrent transaction may wish to obtain. This is an important issue, but
enabling repeatable read isn’t the only way to resolve it.
Let’s assume you’re using versioned data, something that Hibernate can do for
you automatically. The combination of the (mandatory) persistence context
cache and versioning already gives you most of the nice features of repeatable
read isolation. In particular, versioning prevents the second lost updates problem,
and the persistence context cache also ensures that the state of the persistent
instances loaded by one transaction is isolated from changes made by other transactions.
So, read-committed isolation for all database transactions is acceptable if
you use versioned data.
Repeatable read provides more reproducibility for query result sets (only for
the duration of the database transaction); but because phantom reads are still
possible, that doesn’t appear to have much value. You can obtain a repeatable-
read guarantee explicitly in Hibernate for a particular transaction and piece
of data (with a pessimistic lock).
Setting the transaction isolation level allows you to choose a good default locking
strategy for all your database transactions. How do you set the isolation level?
Setting an isolation levelEvery JDBC connection to a database is in the default isolation level of the DBMS—
usually read committed or repeatable read. You can change this default in the
DBMS configuration. You may also set the transaction isolation for JDBC connections
on the application side, with a Hibernate configuration option:
hibernate.connection.isolation = 4
Hibernate sets this isolation level on every JDBC connection obtained from a
connection pool before starting a transaction. The sensible values for this option
are as follows (you may also find them as constants in java.sql.Connection):
■ 1—Read uncommitted isolation
■ 2—Read committed isolation
■ 4—Repeatable read isolation
■ 8—Serializable isolation
Note that Hibernate never changes the isolation level of connections obtained
from an application server-provided database connection in a managed environment!
You can change the default isolation using the configuration of your application
server. (The same is true if you use a stand-alone JTA implementation.)
As you can see, setting the isolation level is a global option that affects all connections
and transactions. From time to time, it’s useful to specify a more restrictive
lock for a particular transaction. Hibernate and Java Persistence rely on
optimistic concurrency control, and both allow you to obtain additional locking
guarantees with version checking and pessimistic locking.
An optimistic approach always assumes that everything will be OK and that conflicting
data modifications are rare. Optimistic concurrency control raises an
error only at the end of a unit of work, when data is written. Multiuser applications
usually default to optimistic concurrency control and database connections
with a read-committed isolation level. Additional isolation guarantees are
obtained only when appropriate; for example, when a repeatable read is required.
This approach guarantees the best performance and scalability.
Understanding the optimistic strategy
To understand optimistic concurrency control, imagine that two transactions read
a particular object from the database, and both modify it. Thanks to the read-committed
isolation level of the database connection, neither transaction will run into any dirty reads. However, reads are still nonrepeatable, and updates may also be
lost. This is a problem you’ll face when you think about conversations, which are
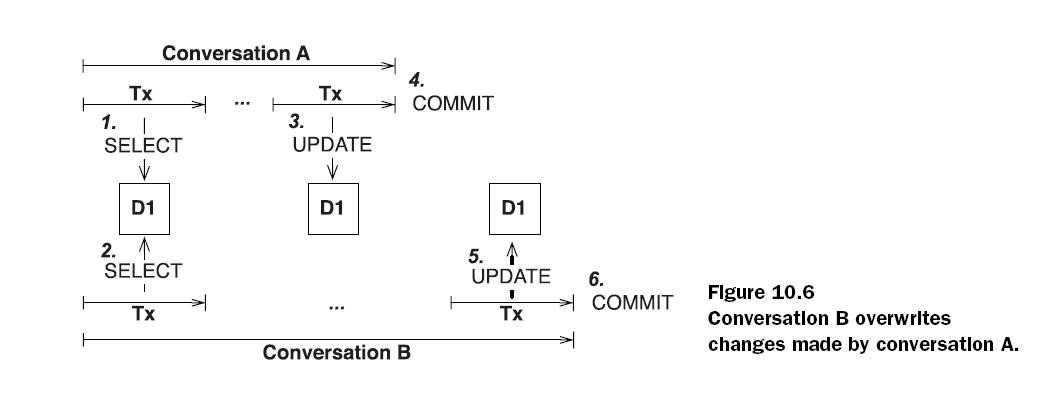
atomic transactions from the point of view of your users. Look at figure 10.6.
Let’s assume that two users select the same piece of data at the same time. The
user in conversation A submits changes first, and the conversation ends with a successful
commit of the second transaction. Some time later (maybe only a second),
the user in conversation B submits changes. This second transaction also commits
successfully. The changes made in conversation A have been lost, and (potentially
worse) modifications of data committed in conversation B may have been based
on stale information.
You have three choices for how to deal with lost updates in these second transactions
in the conversations:
■ Last commit wins—Both transactions commit successfully, and the second
commit overwrites the changes of the first. No error message is shown.
■ First commit wins—The transaction of conversation A is committed, and the
user committing the transaction in conversation B gets an error message.
The user must restart the conversation by retrieving fresh data and go
through all steps of the conversation again with nonstale data.
■ Merge conflicting updates—The first modification is committed, and the transaction
in conversation B aborts with an error message when it’s committed.
The user of the failed conversation B may however apply changes selectively,
instead of going through all the work in the conversation again.
If you don’t enable optimistic concurrency control, and by default it isn’t enabled,
your application runs with a last commit wins strategy. In practice, this issue of lost
updates is frustrating for application users, because they may see all their work
lost without an error message.
 Figure 10.6Conversation B overwriteschanges made by conversation A.
Figure 10.6Conversation B overwriteschanges made by conversation A.Obviously, first commit wins is much more attractive. If the application user of
conversation B commits, he gets an error message that reads, Somebody already committed
modifications to the data you’re about to commit. You’ve been working with stale
data. Please restart the conversation with fresh data. It’s your responsibility to design
and write the application to produce this error message and to direct the user to
the beginning of the conversation. Hibernate and Java Persistence help you with
automatic optimistic locking, so that you get an exception whenever a transaction
tries to commit an object that has a conflicting updated state in the database.
Merge conflicting changes, is a variation of first commit wins. Instead of displaying
an error message that forces the user to go back all the way, you offer a dialog that
allows the user to merge conflicting changes manually. This is the best strategy
because no work is lost and application users are less frustrated by optimistic concurrency
failures. However, providing a dialog to merge changes is much more
time-consuming for you as a developer than showing an error message and forcing
the user to repeat all the work. We’ll leave it up to you whether you want to use
this strategy.
Optimistic concurrency control can be implemented many ways. Hibernate
works with automatic versioning.
Enabling versioning in HibernateHibernate provides automatic versioning. Each entity instance has a version,
which can be a number or a timestamp. Hibernate increments an object’s version
when it’s modified, compares versions automatically, and throws an exception if a
conflict is detected. Consequently, you add this version property to all your persistent
entity classes to enable optimistic locking:
public class Item {
...
private int version;
...
}
You can also add a getter method; however, version numbers must not be modified
by the application. The <version> property mapping in XML must be placed
immediately after the identifier property mapping:
<class name="Item" table="ITEM">
<id .../>
<version name="version" access="field" column="OBJ_VERSION"/>
...
</class>
The version number is just a counter value—it doesn’t have any useful semantic
value. The additional column on the entity table is used by your Hibernate application.
Keep in mind that all other applications that access the same database can
(and probably should) also implement optimistic versioning and utilize the same
version column. Sometimes a timestamp is preferred (or exists):
public class Item {
...
private Date lastUpdated;
...
}
<class name="Item" table="ITEM">
<id .../>
<timestamp name="lastUpdated"
access="field"
column="LAST_UPDATED"/>
...
</class>
In theory, a timestamp is slightly less safe, because two concurrent transactions
may both load and update the same item in the same millisecond; in practice,
this won’t occur because a JVM usually doesn’t have millisecond accuracy (you
should check your JVM and operating system documentation for the guaranteed
precision).
Furthermore, retrieving the current time from the JVM isn’t necessarily safe in
a clustered environment, where nodes may not be time synchronized. You can
switch to retrieval of the current time from the database machine with the
source="db" attribute on the
mapping. Not all Hibernate SQL dialects
support this (check the source of your configured dialect), and there is
always the overhead of hitting the database for every increment.
We recommend that new projects rely on versioning with version numbers, not
timestamps.
Optimistic locking with versioning is enabled as soon as you add a
or a <timestamp> property to a persistent class mapping. There is no other switch.
How does Hibernate use the version to detect a conflict?
Automatic management of versions
Every DML operation that involves the now versioned Item objects includes a version
check. For example, assume that in a unit of work you load an Item from the
database with version 1. You then modify one of its value-typed properties, such as
the price of the Item. When the persistence context is flushed, Hibernate detects
that modification and increments the version of the Item to 2. It then executes
the SQL UPDATE to make this modification permanent in the database:
update ITEM set INITIAL_PRICE='12.99', OBJ_VERSION=2
where ITEM_ID=123 and OBJ_VERSION=1
If another concurrent unit of work updated and committed the same row, the
OBJ_VERSION column no longer contains the value 1, and the row isn’t updated.
Hibernate checks the row count for this statement as returned by the JDBC
driver—which in this case is the number of rows updated, zero—and throws a
StaleObjectStateException. The state that was present when you loaded the
Item is no longer present in the database at flush-time; hence, you’re working
with stale data and have to notify the application user. You can catch this exception
and display an error message or a dialog that helps the user restart a conversation
with the application.
What modifications trigger the increment of an entity’s version? Hibernate
increments the version number (or the timestamp) whenever an entity instance is
dirty. This includes all dirty value-typed properties of the entity, no matter if
they’re single-valued, components, or collections. Think about the relationship
between User and BillingDetails, a one-to-many entity association: If a Credit-
Card is modified, the version of the related User isn’t incremented. If you add or
remove a CreditCard (or BankAccount) from the collection of billing details, the
version of the User is incremented.
If you want to disable automatic increment for a particular value-typed property
or collection, map it with the optimistic-lock="false" attribute. The
inverse attribute makes no difference here. Even the version of an owner of an
inverse collection is updated if an element is added or removed from the
inverse collection.
As you can see, Hibernate makes it incredibly easy to manage versions for optimistic
concurrency control. If you’re working with a legacy database schema or
existing Java classes, it may be impossible to introduce a version or timestamp
property and column. Hibernate has an alternative strategy for you.